Pourquoi un code de saisie ?
Lorsqu’on a pour ambition l’encodage informatique de données musicales, la première idée qui vient à l’esprit est d’utiliser l’un des logiciels d’édition musicale qui se sont répandus ces dernières années, et que musiciens et musicologues ont, au prix de louables efforts, appris à manier. C’est là que les problèmes commencent… Entre les adeptes de « Da capo© », les fanatiques de « Grieg® » et les inconditionnels de « Ionico™ » ou de tout autre éditeur wysiwyg, la guerre de religion est programmée.
Mais une équipe de projet qui serait parvenue à faire son choix parmi ces produits concurrents sans provoquer de schisme irrémédiable n’en serait encore qu’au début de ses peines : s’il est vrai que ces logiciels ont acquis quelques lettres de noblesse dans l’art de disposer harmonieusement des objets graphiques dans un espace bidimensionnel, ils demeurent largement inopérants dans celui de recueillir des données. Une fois que l’utilisateur a, clic après clic, déplacé, agrandi, modifié, recomposé la portée musicale qui s’affiche sous ses yeux, les fichiers qu’il parvient à enregistrer sur son disque dur sont une vraie bouteille à l’encre. Le plus souvent cryptique, soumis aux caprices de leurs concepteurs et à des changements de version imprévisibles, leur format a de quoi donner des cheveux blancs à qui se serait assigné pour tâche d’en extraire des données exploitables. Et ce, sans même prendre en compte le fait que ces logiciels ignorent tout de la logique propre à la notation mensurale et que, transcrivant de la musique médiévale, l’utilisateur doit constamment user d’expédients pour arriver à un rendu graphique acceptable. Bref, chercher à contrôler finement les données encodées à l’aide des logiciels du commerce équivaut à peu près à manipuler des timbres-poste en ayant chaussé des gants de boxe.
Pourquoi, alors, ne pas prendre le problème par l’autre bout ? Si le but à atteindre est un fichier structuré selon le standard XML, pourquoi ne pas rédiger directement un tel fichier à la main ? Tout simplement parce que XML est un standard extraordinairement verbeux. Pour décrire précisément ne serait-ce qu’une seule note de musique avec la syllabe qui lui est associée, il requiert d’ordinaire un texte de plus de cent caractères :
<note dur="semibrevis" num="3" numbase="2" oct="4" pname="g"><verse n="1" lineid="0" color="#000000"><syl wordpos="i">non</syl></verse></note>
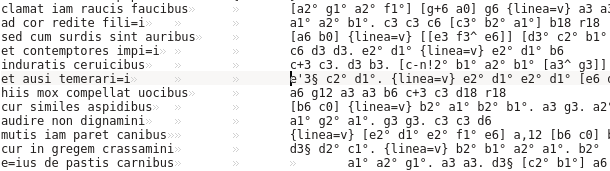
Voilà de quoi lever une armée de dactylographes stakhanovistes… Le code dont nous nous servons pour saisir les données d’un manuscrit, baptisé code minimÆ, dit exactement la même chose en six caractères :
non g3
Inquiets tout d’abord à l’idée de devoir saisir du code directement dans un éditeur de texte, les membres de l’équipe en charge de la transcription des sources acquièrent vite de l’aisance. D’une part, le code est suffisamment intuitif et mnémotechnique pour que la courbe d’apprentissage soit rapide. D’autre part, ils ont à disposition un validateur en ligne qui leur permet, sans installer le moindre logiciel dédié, de visualiser le résultat de leur travail, via LilyPond en notation moderne ou via verovio en notation mensurale. De notre côté, nous maîtrisons de bout en bout la chaîne qui va de la saisie à la base de données, ce qui n’est pas un mince bénéfice.